
Anatomía del nuevo modelo de memoria en C# 16: Contratos, Guardias y Código Inseguro
Hace poco charlamos superficialmente sobre los cambios que se vienen en la seguridad de memoria de C#, pero hoy vamos a ensuciarnos las manos. El equipo de .NET está preparando para C# 16 (con vistas previas desde .NET 11 y versión final en .NET 12) una revolución total inspirada fuertemente en Rust y Swift.
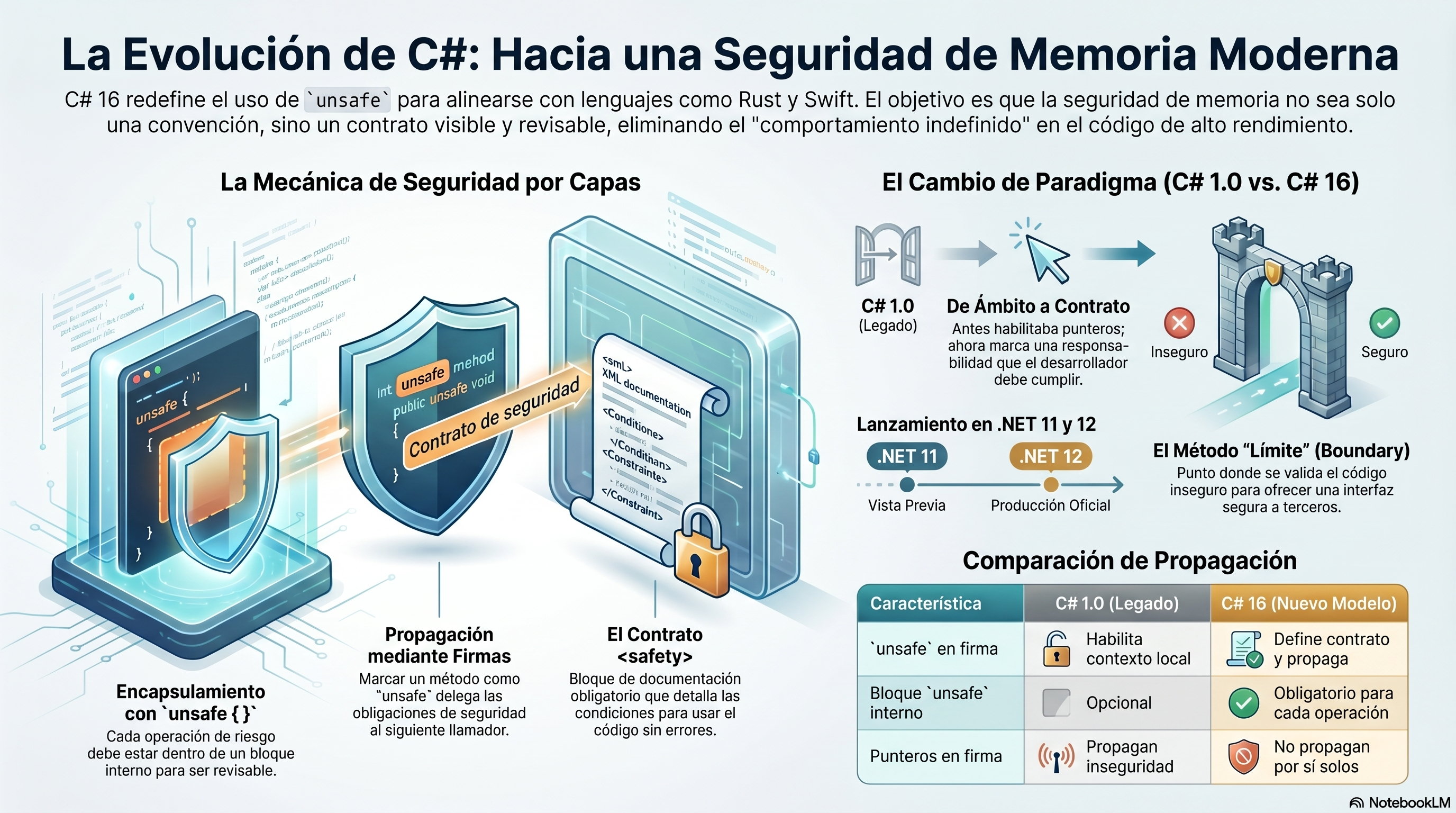
La premisa es simple pero poderosa: la palabra clave unsafe dejará de ser una simple configuración de sintaxis para convertirse en un contrato estricto de seguridad.
¿Por qué es esto necesario y cómo se ve en el código? Vamos a desarmarlo paso a paso.
El problema con el modelo de C# 1.0
Desde la primera versión de C#, agregar unsafe a un método o tipo establecía un “contexto inseguro”. Esto nos daba superpoderes: declarar punteros, desreferenciarlos y manipular la memoria directamente.
El problema es que este modelo operaba casi enteramente por convención. Mirá este ejemplo conceptual de cómo funciona hoy:
// Modelo actual (C# 1.0)
public unsafe void M(byte* ptr)
{
// Hacemos algo peligroso con ptr
}
public void Caller(byte* ptr)
{
// Caller puede llamar a M sin ninguna ceremonia especial
M(ptr);
}
Si un método exponía punteros (como byte*), el compilador forzaba al llamador a estar en un contexto inseguro. ¡Pero si usabas IntPtr, podías evadir esta regla! Esto se conoce como “contrabando de punteros” (pointer smuggling), donde podías invocar métodos altamente destructivos desde código 100% seguro sin ninguna advertencia. Todo dependía de que el desarrollador leyera la documentación y “fuera cuidadoso”.
El nuevo paradigma: Los 4 pilares de C# 16
El nuevo modelo de C# 16 exige que cualquier operación que pueda violar la integridad de la memoria viva sea explícita. Esto se logra mediante cuatro mecanismos que trabajan en conjunto:
- Bloques internos
unsafe { }obligatorios: Para ejecutar una operación insegura (como desreferenciar un puntero), ahora debes envolverla en un bloque. - Propagación o Supresión: Si tu método no puede garantizar la seguridad, debe marcarse como
unsafeen su firma (propagación). Si asumes la responsabilidad validando los datos, no llevas la marca (supresión). - Documentación de Seguridad (
/// <safety>): Un bloque XML obligatorio que explica el contrato. - Guardias de Seguridad: Validaciones explícitas que protegen el código interno.
Veamos cómo se aplica esto al mundo real.
1. Propagación de responsabilidades: El caso de Marshal.ReadByte
Tomemos una API clásica: Marshal.ReadByte. Toma un puntero opaco (IntPtr) y un índice, y lee ese byte. Bajo el nuevo modelo, su implementación se vería más o menos así:
/// <summary>Lee un byte de la memoria no administrada.</summary>
/// <safety>
/// El llamador debe garantizar que `ptr + ofs` apunte a
/// un byte de memoria que pueda ser leído de forma segura.
/// </safety>
public static unsafe byte ReadByte(IntPtr ptr, int ofs)
{
byte* addr = (byte*)ptr; // Un simple cast numérico, no es inseguro.
// SAFETY: Confiamos en que el llamador cumple el contrato de <safety>.
unsafe
{
return addr[ofs]; // ACÁ está el peligro: la desreferencia.
}
}
¿Qué está pasando aquí?
- Fijate en la etiqueta
/// <safety>. Este es el contrato formal. Los analizadores de código te marcarán un error si haces un métodounsafey olvidas este comentario. - El comentario interno
// SAFETY:es una nota para el revisor del código, indicando qué suposiciones se están haciendo. - La desreferencia real (
addr[ofs]) está aislada dentro del bloqueunsafe { }. El compilador de C# 16 no te dejará hacerlo sin ese bloque. - La firma tiene
unsafe. Esto propaga la obligación: quien llame aReadByteahora está obligado a usar también un bloqueunsafe { }en su código.
2. Supresión y Guardias: Protegiendo la frontera
¿Qué pasa cuando queremos crear una función que el resto de nuestra aplicación (código seguro) pueda llamar sin problemas? Aquí entran los métodos de frontera (boundary methods).
Estos métodos contienen bloques unsafe { } internamente, pero no llevan la palabra clave unsafe en su firma. Para lograr esto sin romper el sistema, utilizan Guardias.
Veamos la estrategia que usa internamente String.CopyTo para copiar memoria:
public void CopyTo(int sourceIndex, char[] destination, int destinationIndex, int count)
{
// 1. Guardias de Seguridad (Safety Guards)
ArgumentNullException.ThrowIfNull(destination);
ArgumentOutOfRangeException.ThrowIfNegative(count);
ArgumentOutOfRangeException.ThrowIfNegative(sourceIndex);
ArgumentOutOfRangeException.ThrowIfNegative(destinationIndex);
// (Otras comprobaciones de límites omitidas por brevedad...)
// 2. Frontera segura: Ya validamos todo, la memoria es confiable.
// SAFETY: Las guardias anteriores aseguran que los punteros no
// se saldrán de los límites de los arreglos.
unsafe
{
Buffer.Memmove(
ref Unsafe.Add(ref MemoryMarshal.GetArrayDataReference(destination), destinationIndex),
ref Unsafe.Add(ref _firstChar, sourceIndex),
(uint)count);
}
}
Cada ThrowIf... es una guardia. Si no validáramos que count no es negativo, al castearlo a uint se convertiría en un número gigantesco, lo que causaría que Buffer.Memmove leyera o escribiera memoria arbitraria (el temido Undefined Behavior o UB). Al poner estas guardias, el método asume la responsabilidad y “suprime” la inseguridad, ofreciendo una API limpia y segura al consumidor.
3. El nivel experto: Campos inseguros (unsafe fields)
C# 16 introduce algo sumamente interesante para arquitecturas complejas: aplicar unsafe a los campos (variables de clase).
A veces, el peligro no está en llamar a una API del sistema operativo, sino en la diferencia entre “lo que el sistema de tipos de C# puede ver” y “lo que tu clase promete mantener”.
Imaginá que creás un NativeBuffer que maneja memoria externa:
public sealed class NativeBuffer : IDisposable
{
// Este campo es inseguro porque su validez depende de un contrato
// que el tipo debe mantener de forma manual.
private unsafe byte* _ptr;
public readonly int Length;
public NativeBuffer(int length)
{
Length = length;
unsafe { _ptr = (byte*)NativeMemory.Alloc((nuint)length); }
}
public void Dispose()
{
unsafe
{
// Invalida el puntero
byte* p = _ptr;
_ptr = null;
if (p != null) NativeMemory.Free(p);
}
}
}
En este caso, la variable _ptr está marcada como unsafe porque lleva consigo un invariante: “Este puntero siempre apunta a un bloque de tamaño Length, o es null”. Marcar el campo obliga a que cualquier lectura o escritura que se haga sobre él —incluso en métodos privados dentro de la misma clase— deba ocurrir dentro de un bloque unsafe { }. ¡Se acabó el arruinar la memoria internamente por accidente!
La era de la IA y el nuevo estándar
¿Por qué Microsoft invierte tanto en esto ahora? Además de que la seguridad de memoria es una prioridad para toda la industria, la generación de código mediante IA ha cambiado las reglas del juego.
Los asistentes de IA tienden a “alucinar” código que parece correcto pero que ignora contratos implícitos, lo que introduce graves vulnerabilidades. Con este nuevo modelo, los errores ya no serán lógicos u ocultos, sino que el compilador rechazará inmediatamente las compilaciones que intenten invocar código inseguro sin el bloque unsafe { } correspondiente o sin respetar la propagación. Un error de compilación es mil veces mejor que horas de revisión de código manual.
Cabe destacar que todo esto será opt-in inicialmente, activable mediante una nueva propiedad a nivel proyecto en el .csproj. Sin embargo, la meta de .NET es clara: hacer que este nivel de seguridad y rigor se convierta en la nueva normalidad.
A mí, personalmente, me parece fascinante cómo lenguajes históricamente tan distintos se están nutriendo entre sí para resolver la crisis de seguridad de memoria de la última década.
¿Ustedes ya manejan código unsafe en sus proyectos en producción? ¿Creen que este rigor extra será un obstáculo o una bendición? ¡Los leo en los comentarios!
Fuente consultada:
Lander, R. (2026). Improving C# Memory Safety — .NET Blog. Microsoft Dev Blogs.